Table of Contents
Tipps zur Massen-Nachbearbeitung und -Archivierung (z.B. von Nachlässen)
Ordnerstrukturen
Angenommen wird, dass man (vor der Archivierung) folgende Ordnerstruktur hat:
Hauptordner
├── Digitalisat_1
│ ├── CR2
│ ├── info
│ ├── pageimg
│ ├── raw
│ │ └── extra
│ └── user
├── Digitalisat_2
│ ├── CR2
│ ├── info
│ ├── pageimg
│ ├── raw
│ │ └── extra
│ └── user
└── Digitalisat_3
├── CR2
├── info
├── pageimg
├── raw
│ └── extra
└── user
Ein Unterordner sieht dabei nach Fertigstellung aller Bilder z. B. so aus:
Digitalisat_1 ├── info │ ├── colorchecker.dng │ ├── graukarte.dng │ ├── projekt.atn │ └── readme.txt ├── CR2 │ ├── 0001.CR2 │ └── 0002.CR2 ├── raw │ ├── 0001.dng │ ├── 0002.dng │ └── extra │ └── zzzz.dng ├── user │ ├── 0001.tif │ ├── 0002.tif │ └── zzzz.tif ├── pageimg │ ├── 0001.jpg │ ├── 0002.jpg │ └── zzzz.jpg └── Digitalisat_1.pdf
Tipps
1. Nachbearbeitung und Archivierung trennen
Nachbearbeitung und Archivierung trennt man am besten und führt batchweise jeweils alle Einzelschritte für alle Digitalisate (Digitalisat_1, …) aus. Zuerst werden alle Dateien umbenannt, dann für alle der Weißabgleich durchgeführt etc. Später bei der Archivierung genauso: Erst werden alle JPEGs auf online_permanent, dann alle TIFFs auf archive_data kopiert usw.
2. Zur Anwendung des Weißabgleichs
Man kann in Bridge den Hauptordner öffnen und dann auf Ansicht > Elemente in Unterordnern anzeigen klicken. Dann werden alle CR2s angezeigt und man kann wie gewohnt den Weißabgleich auf alle anwenden.
3. Zur Konvertierung der CR2- in DNG-Dateien
Befinden sich die CR2 Dateien direkt im Ordner CR2 (und nicht in Unterordnern links/rechts), können die CR2s aller Digitalisate mit folgenden Befehlen automatisch konvertiert und im jeweiligen Unterordner raw gespeichert werden.
Im Terminal geht man zunächst in den übergeordneten Ordner:
cd /Volumes/digigroup/Hauptordner
Anschließend führt man folgenden Befehl aus:
for d in ./*/ ; do (cd "$d" && /Applications/Adobe\ DNG\ Converter.app/Contents/MacOS/Adobe\ DNG\ Converter -d "$(pwd)/raw" CR2/*.CR2); done
Der Befehl ignoriert die Ordner mit rechts/links-Aufteilung. Diese müssen einzeln mit dem Adobe DNG Converter umgewandelt werden.
4. Begradigung
Man öffnet alle dng-Dateien aus raw in CameraRaw, markiert siee (soweit sie gleich ausgerichtet sind) und wendet durch Klicken von a eine Begradigung auf alle an.
5. Zur Erzeugung der JPGs und TIFs
Man benutzt eine Projekt-spezifsche Aktionsdatei in Photoshop. Man öffnet die projekt.atn und stellt den Speicherort für die TIFs und JPGs auf den Hauptordner, also z.B. auf Digitalisat_1 und nicht – wie gewöhnlich – auf pageimg und user in z.B. Digitalisat_1. Danach verschiebt man die JPGs manuell in den pageimg-Ordner und die TIFs in den user-Ordner. So muss man nicht jedesmal manuell die ganze Post durchgehen und den Speicherort neu festlegen, wenn man ein neues Digitalisat_* beginnt.
6. Zur Erzeugung der PDFs (falls gefordert)
Im Terminal geht man zunächst in den übergeordneten Ordner:
cd /Volumes/digigroup/Hauptordner
Anschließend drückt man F14 und Enter. Hierdurch wird folgendes Script ausgeführt:
#!/bin/sh
for d in ./*/ ; do (cd "$d" && img2pdf pageimg/*.jpg -o ${PWD##*/}.pdf); done
(Ort des Scripts: /Volumes/digigroup/zzz_Scripte\ \&\ Vorlagen/autopdf.sh)
Dadurch werden automatisch und gleichzeitig für alle Digitalisat_*-Ordner die JPEGs aus dem jeweilgen pageimg-Ordner zu einer PDF-Datei zusammengefasst. Die PDF-Datei wird dabei automatisch nach dem Ordner benannt, in dem sie sich befindet, also z. B. Digitalisat_1.pdf.
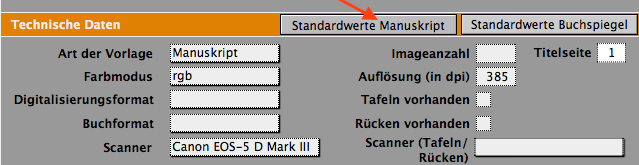
7. „Standardwerte Manuskript“ im Filemaker
Es gibt einen neuen Button im Filemaker, der die folgenden Daten automatisch einträgt. Hier wird vorausgesetzt, dass es sich um einen Nachlass handelt, der vorrangig aus Manuskripten besteht und der mit dem TCCS digitalisiert wurde. Die Imageanzahl und eventuell notwendige weitere Daten muss man manuell eintragen. Die dpi-Zahl muss man im FileMaker-Script vorher anpassen.
8. IDs schneller generieren und einfügen
Man kann jetzt alle IDs direkt im Filemaker generieren und einfügen lassen. Dazu entweder einfach auf die Beschriftung des jeweiligen Feldes klicken – ein Script holt sich dann eine ID von der Website und fügt sie automatisch ein – …

… oder im Filemaker unter Scripts auf IDs_vergeben klicken, um alle drei gleichzeitig einzufügen.
9. Vor der Archivierung: Dateien prüfen
Mit folgendem Befehl lässt sich grob überprüfen, ob alle Dateien vorhanden sind. Man geht im Terminal zunächst in den übergeordneten Ordner:
cd /Volumes/digigroup/Hauptordner
Anschließend drückt man F13 und Enter, um automatisch folgendes Script laufen zu lassen:
#!/bin/sh
clear
printf " \
\e[7m*********************************************\e[27m\n\n \
Es sind in \e[35m$(printf '%s\n' "${PWD##*/}")\e[39m\n\n \
in \e[34m$(find ./* -maxdepth 0 -type d | grep -c .)\e[39m Unterordnern ...\n\n \
\e[34m$(find . -type f -name "zzzz.dng" | grep -c .)\e[39m DNG-Colorchecker,\n \
\e[34m$(find . -type f -name "zzzz.jpg" | grep -c .)\e[39m JPG-Colorchecker,\n \
\e[34m$(find . -type f -name "zzzz.tif" | grep -c .)\e[39m TIF-Colorchecker,\n \
\e[34m$(find . -type f -name "*.pdf" | grep -c .)\e[39m PDFs,\n\n \
\e[32m$(find . -type f -name "*.jpg" | grep -c .)\e[39m JPGs,\n \
\e[32m$(find . -type f -name "*.tif" | grep -c .)\e[39m TIFs,\n \
\e[32m$(exiftool . -r -ext pdf | grep "Page Count" | cut -c 35-38 | awk '{s+=$1} END {printf "%.0f", s}')\e[39m zu PDF zusammengefasste JPGs,\n\n \
\e[93m$(find . -type f -name "*.CR2" | grep -c .)\e[39m CR2s,\n \
\e[93m$(find ./*/raw -type f -name "*.dng" | grep -c -v "zzzz")\e[39m DNGs in /raw,\n\n \
\e[36m$(find . -type f -mtime -2 | grep -c readme)\e[39m aktualisierte readme.txt-Dateien,\n \
\e[36m$(find . -type f | grep -c index.meta)\e[39m index.meta-Dateien\n\n \
...vorhanden.\n\n \
Leere Ordner:\n \
\e[91m$(find . -type d -empty)\e[39m\n\n \
Falsch benannt:\n \
\e[31m$(find . -type f | grep IMG_)\e[39m \
\e[31m$(find . -type f | grep -)\e[39m \
\e[31m$(find . -type f | grep -e '^\s[^\s]' -e '[^\s]\s$' -e '[^\s]\s[^\s]')\e[39m \
\e[31m$(find . -type f | grep canon_workflow)\e[39m\n \
\e[7m*********************************************\e[27m\n\n"
(Ort des Scripts: /Volumes/digigroup/zzz_Scripte\ \&\ Vorlagen/filechecker.sh)
Das Ergebnis könnte dann z.B. so aussehen:
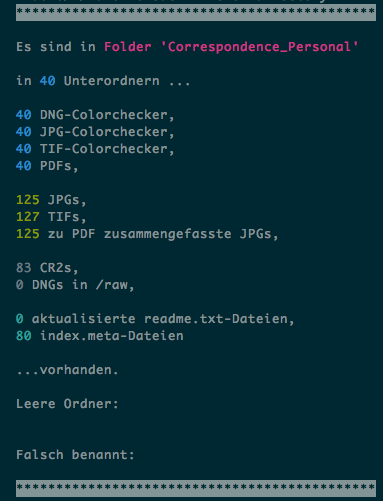
Das Script sucht auch nach typischerweise falsch benannten Dateien (z. B. IMG_0001.jpg oder 0001 Kopie.jpg statt 0001.jpg etc.):

Das Script funktioniert vollständig nur, bevor man die Ordner per FileMaker „vorbereitet“, also in Unterordner, die nach IDs benannt sind, verschoben hat.
Man kann durch das Script z. B. sehen, ob es eine Differenz der Anzahl von JPGs und TIFs gibt, ob man z.B. eine readme.txt-Datei vergessen hat (es zeigt die Anzahl der innerhalb der letzten 2 Tage aktualisierten readme.txts an) oder ob es einen leeren Ordner gibt (was i. d. R. nicht sein sollte) etc. Natürlich ist das nur ein recht grober Überblick und es kann z. B. sein, dass es durchaus unterschiedlich viele TIFs und JPGs geben muss (wenn man z. B. auch mit dem Flachbettscanner gescannt hat). Das Script findet auch nicht alle falsch benannten Dateien. Es ersetzt also nicht die Endkontrolle, aber hilft bei der Fehlersuche.
10. Vor der Archivierung: Dateinamen prüfen
Darauf achten, dass keine Sonderzeichen im Dateinamen im Filemaker und im eigentlichen Ordernamen vorkommen (keine Leerezeichen, Umlaute, Punkte etc.), sondern nur Unterstriche. Beispiel:
falsch:
Letter (Schücking, 28-02-1974)
richtig:
Letter_Schuecking_28_02_1974
11. Vor der Archivierung: Dateipfad ändern
Damit die Scripte im Filemaker zur Archivierung funktionieren, müssen die einzelnen Ordner (Digitalisat_1, Digitalisat_2, …) direkt auf digigroup liegen. Am besten man macht Schritt 1 Vorbereitung digigroup noch im Hauptordner und kopiert (nicht verschiebt) dann alle Digitalisat_*-Ordner nach digigroup, bevor man Schritt 2 Copy online_permanent startet. Wenn alles fertig ist, können die Dateien von digigroup wieder gelöscht werden und die Originaldateien verbleiben im Hauptordner.
